【30分で完了】ConoHa VPSへSSH接続する方法を解説
SANA Sanao Tech Lab
こんにちは。
今回は「Pythonを使用してChatGPTのAPIを呼び出し、独自のAPIを作成します。最終的に、この作成したAPIをWebサーバーにデプロイし、HTTP通信を介して利用可能にする手順」を解説します。
今回はも真面目に取り組みます!
あえて「真面目」という言葉を使ったのは、ただ単にPythonでコード書いて外部APIを呼び出して終わりということではなく、以下のポイントに留意して開発を進めたいと思います。
・層別アーキテクチャを採用・・「APIアクセス層」「ロジック層」「エンドポイント層」を分けて開発することにより、保守性及び再利用性を向上させる。
・エラーハンドリング・・エラーハンドリングを適切に行うことで、不具合が生じた際の原因特定作業を手早く実施できるようにする。
・Webサーバへのデプロイ手順の確立・・デプロイプロセスを明確にすることで、スムーズに何回も繰り返せる移行を可能にする。
今回のシステムはChatGPTのAPIを呼び出してその結果をHTTP経由で公開するシンプルなAPIとなっています。しかし、将来的にドンドン外部APIを追加して独自のサービスを作れるようにしたいという願望がありますので、「拡張性」「再利用性」「保守性」を考慮した開発をします。
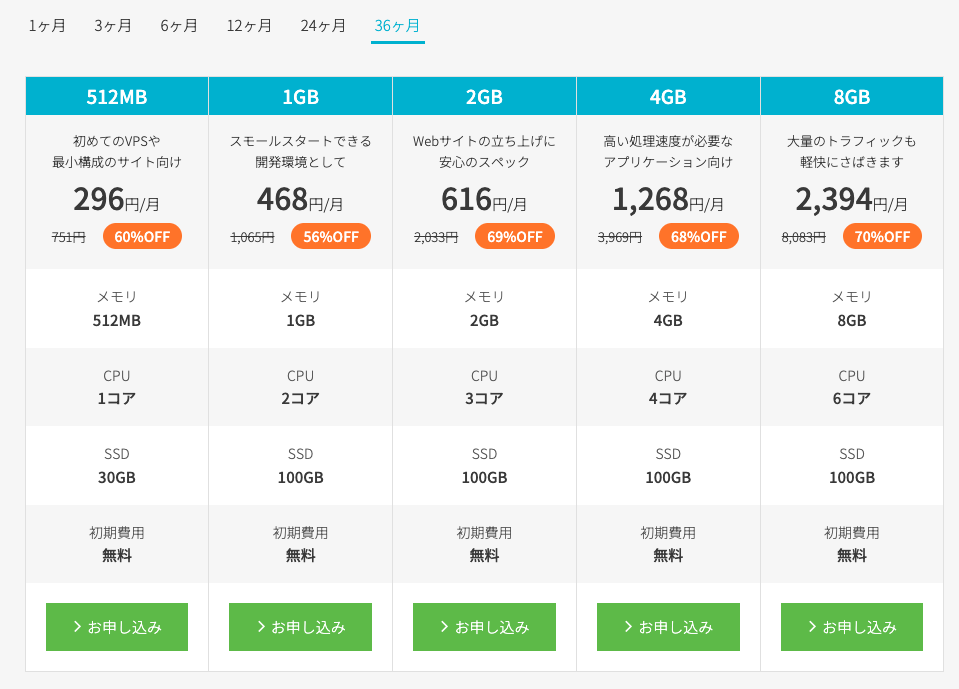
そんな色々遊べるConoHa VPSは月額500円程度で使い放題なのでオススメです。下記のボタンからのお申し込みで最大1ヶ月無料となりますので是非お試しください。
今回開発を行った環境は以下となります。
<接続先VPSサーバ情報>
サーバ:ConoHa VPS
OS:Ubuntu22.04
Python:3.10.12
Flask:3.0.2
Apache:2.4.52
また、Python開発をする際には仮想環境を作成することで、プロジェクトごとの環境依存関係(ライブラリのバージョンetc)の管理が容易になります。環境がぐちゃぐちゃだと想定外の不具合が発生する可能性がありますので強くオススメです。
以下の記事で解説していますので、興味ある方は一読ください。

今回の開発のロードマップを以下に示します。
・開発用のフォルダ構成を決める。
・ChatGPTのAPIキー取得する。
・『Flask』のフレームワークを使用してひたすらコードを書く。
・エラーハンドル用の処理を作成してデコレーターとして使用する。
・開発環境と同様のライブラリをWebサーバへインストールする。
・『WSGI』を使用して実装したソースをWebサーバへデプロイする。
・外部からHTTP通信経由でAPIが利用可能かを確かめる。
層別アーキテクチャを考慮して開発用のフォルダ構成は以下のようにします。
my_project/
├── src/ #ソースのディレクトリ
│ ├── init.py #おまじない
│ ├── api/ #外部APIへアクセスするファイル群(「APIアクセス層」に対応)
│ ├── logic/ #ビジネスロジック記述したファイル群(「ロジック層」に対応)
│ ├── app.py #URLのエンドポイントを定義(「エンドポイント層」に対応)
│ ├── utils/ #エラー処理等の共通処理を記述したファイル群
│ └── config.py #設定情報(APIキー)を含むファイル
├── tests/ #テストコードを記述したファイル群
├── docs/ #API仕様書ファイル群
├── README.md #プロジェクト概要等を記述したファイル
├── requirements.txt #外部Pythonパッケージ依存関係リスト化したファイル
└── setup.py # PJをPythonパッケージ配布するための設定ファイル「APIアクセス層」「ロジック層」「エンドポイント層」に加えて、チェック処理などの共通処理をまとめる「utils」フォルダ、APIキー情報や定数管理情報などを管理する「config.py」を作成しています。
「tests」フォルダや「README.md」「setup.py」については本記事では触れませんのでご承知おきください。
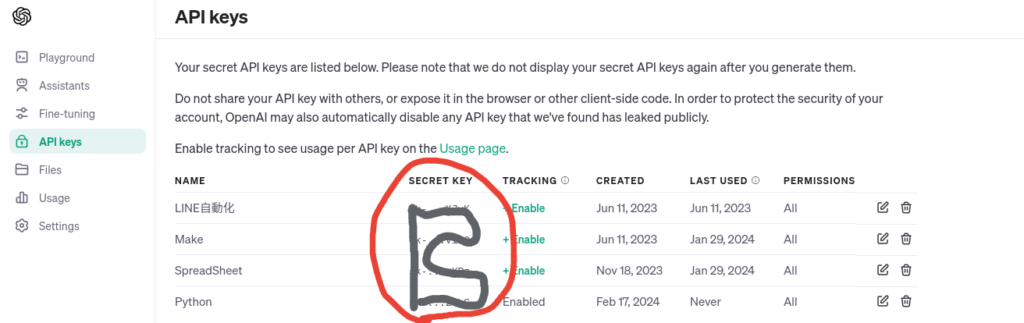
OpenAIサイトの左にあるAPI keysからAPIキー情報を作成します。一度、秘密キーが表示された後にブラウザを閉じると確認できなくなりますのでメモしておきましょう。
「Flask」と「requests」を先んじてインストールしおきます。
pip3 install Flask requests 簡単な概要について以下にまとめます。
「requests」・・PythonでHTTPリクエストを簡単に送れるライブラリです。Webサイトの内容取得やAPIとの通信に使用されます。
「Flask」・・Pythonで書かれた軽量なWebアプリケーションフレームワークです。開発者は容易にWebサービスやAPIを構築できるのが特徴です。
APIアクセス層はChatGPTのAPIを使ってアクセスする部分となります。
実装のポイントは以下です。
・ChatGPT秘密鍵などの機密又は定数情報は一括管理しているConfigファイルから読み込むようにしました。
・ChatGPTのmodelやtemperature等はConfigファイルで固定するのではなく、APIの汎用性を考えて外部から設定できるようにしました。
・API接続のエラーハンドル用のデコレーター(※)を設定しました。
※デコレーターはPythonにおいて関数やメソッドに新しい機能を動的に追加できます。既存のコードを変更する必要がありません。(チェック処理の追加etcに使えます)
import requests
from utils.api_error_handlers import handle_request_errors
from config import Config
# APIリクエストを送信する関数。エラーハンドリングのためのデコレーターを適用。
@handle_request_errors #デコレーター
def conn_chatgpt_prompt(model, role, max_tokens, temperature, prompt):
# APIリクエスト用のヘッダー。APIキーを使用して認証を行います。
headers = {
"Authorization": f"Bearer {Config.CHATGPT_API_KEY}"
}
# APIリクエストの本文。使用するモデル、プロンプト、トークンの最大数、応答の多様性を制御する温度を指定します。
data = {
"model": model, # 使用するChatGPTモデル。
"messages": [{"role": role, "content": prompt}], # ユーザー(またはシステム)の役割とプロンプトの内容。
"max_tokens": max_tokens, # 応答に含めることができる最大トークン数。
"temperature": temperature # 応答の多様性を制御する温度パラメータ。
}
# 構成されたヘッダーとデータを使用して、ChatGPT APIにPOSTリクエストを送信します。
response = requests.post(Config.CHATGPT_BASE_URL, headers=headers, json=data)
# レスポンスオブジェクトをそのまま返します。
# 呼び出し元は、このレスポンスを解析して必要な情報を抽出する必要があります。
return responseこちらがAPIの接続周りのエラーハンドル用の処理となります。「response.raise_for_status()」で通信のステータスを確認します。成功の200番以外の場合はHTTPError例外を発生させて、例外の種類に応じてエラーメッセージを返却します。
import requests
from config import Config
def handle_request_errors(func):
def wrapper(*args, **kwargs):
try:
response = func(*args, **kwargs)
response.raise_for_status()
return response.json()
except requests.exceptions.HTTPError as http_err:
return {"error": f"HTTP error occurred: {http_err}"}
except requests.exceptions.ConnectionError:
return {"error": "Connection error occurred"}
except requests.exceptions.Timeout:
return {"error": "Timeout occurred"}
except requests.exceptions.RequestException as err:
return {"error": f"An error occurred: {err}"}
except Exception as e:
return {"error": f"An unexpected error occurred: {e}"}
return wrapper
ロジック層ではAPI接続層の部品を使用してChatGPTから返却される回答を取得します。取得した回答に対して「Answer:」の文言を付加して呼び出し元に返却します。
from api.chatgpt_api import conn_chatgpt_prompt
def get_chatgpt_response(model, role, max_tokens, temperature, prompt):
# ChatGPT APIを呼び出して応答を取得
response = conn_chatgpt_prompt(model, role, max_tokens, temperature, prompt)
# 応答から必要なデータを抽出・加工
if 'error' in response:
return "申し訳ありませんが、エラーが発生しました。"
chat_response = response['choices'][0]['message']['content']
# 回答の前に「Answer:」を付加する
customized_response = f"Answer: {chat_response}"
return customized_response最後にエンドポイントとなる部分です。
実装のポイントは以下です。
・エンドポイント層はリクエストから入ってくるインプットデータを取捨選択してその後の処理はロジック層に任せる作りにします。
・「大量のデータ送信が可能」および「データの隠蔽ができる」という点でPOST通信を使用することにしました。さらに、データ連携方式はJSON形式を採用します。
エンドポイント層にて@app.route('/hogehoge'〜)と定義しているので、「https://ホスト名/hogehoge」とアクセスするとアプリを動かすことができます。これもFlaskのフレームワークのおかげです。
# Flaskライブラリと必要なモジュールをインポート
from flask import Flask, jsonify, request
from logic.chatgpt_logic import get_chatgpt_response
# Flaskアプリケーションのインスタンスを作成
app = Flask(__name__)
# /hogehogeエンドポイントにPOSTリクエストが来た場合に実行される関数を定義
@app.route('/hogehoge', methods=['POST'])
def hogehoge():
# リクエストからJSONデータを取得
data = request.get_json()
# リクエストデータから必要な情報を取得
model = data.get('model') # 使用するモデル名
messages = data.get('messages', []) # メッセージリスト(デフォルトは空リスト)
first_message = messages[0] # 最初のメッセージを取得
role = first_message.get('role') # メッセージの送信者の役割
content = first_message.get('content') # メッセージの内容
max_tokens = data.get('max_tokens') # 応答の最大トークン数
temperature = data.get('temperature') # 生成のランダム性を決定する温度パラメータ
# ChatGPT APIにリクエストを送り、応答を取得
chat_response = get_chatgpt_response(model, role, max_tokens, temperature, content)
# 応答を返却
return jsonify(chat_response)
# ファイルが直接実行された場合にのみ、Flaskアプリケーションを起動
if __name__ == '__main__':
app.run(debug=True)
実装が終わったのでローカル環境で動かしてみましょう。
curl -X POST http://127.0.0.1:5000/hogehoge \
-H "Content-Type: application/json" \
-H "Authorization: Bearer [ChatGPTのAPIキー]" \
-d '{
"model": "gpt-3.5-turbo",
"messages": [{"role": "user", "content": "Hello"}],
"max_tokens": 1000,
"temperature": 1.0
}'ローカルホスト(127.0.0.1:5000)は端末によって異なるので、ご自身のものに合わせてください。
APIから返信が帰ってきました。

良い感じです。
それではこちらをWebサーバにデプロイして外部の環境からのHTTP通信経由でも同じように回答が得られるよう作業を進めていきましょう。
以下、Apacheサーバ構築済みが前提となりますのでご認識おきください。
さて、今回の作業をする上で2つの重要なポイントがあります。
・Pythonライブラリのバージョンを開発環境に合わせる
-「requirement.txt」ファイルを用いてライブラリの依存関係を管理します。このファイルには開発環境で使用している全てのPythonパッケージとそのバージョンが記載されており、 コマンドを使ってWebサーバに一括インストールします。
・Apacheにアプリのエンドポイント(app.py)を認識させる
-「mod_wsgi」モジュールを使用してApacheとPythonアプリケーションを連携させます。WSGIファイル内で「app.py」からアプリケーションオブジェクトをインポートし、Apacheがこのオブジェクトを介してリクエストを処理できるようにします。
それでは進めていきましょう。
まず、開発環境にて「requirements.txt」を作成します。今回でいうとプロジェクトフォルダ直下(/my_project/)に移動して以下のコマンドを打ちます。(venv仮想環境で開発してる方はその中で実施してください。)
pip3 freeze > requirements.txtこれで「requirements.txt」にライブラリとそのバージョンが記載されます。
次にWebサーバへこの「requirements.txt」をコピーします。私の場合、「/var/www/app/」直下に配置しました。(venv仮想環境をWebサーバに適用したい場合は事前に仮想環境を作成してその中で作業してください。私の場合、app下にvenvフォルダを作成しました。)
以下のコマンドを実行します。
pip3 install -r requirements.txt完了したら以下のコマンドを使ってインストールされてるかを確認しましょう。
pip3 listこれで終わりです。
開発環境で作成したPythonのアプリケーション資材(例えば、Flaskで構築したapp.py)をWebサーバー上で動作させるためには、
app.py「Apacheさん!ここだよ!」
という設定ができればOKな訳です。それを実現するため「libapache2-mod-wsgi-py3」をインストールして、「wsgi」モジュールを使用できるようにします。「wsgi」モジュールは先程述べましたがApacheとPythonアプリケーションの間に入って良い感じに働いてくれる人です。
インストールのコマンドは以下となります。
sudo apt update
sudo apt install libapache2-mod-wsgi-py3次に「/etc/apache2/sites-available/000-default.conf」のファイルに以下の文言を追加します。このファイルはApache Webサーバーの仮想ホスト設定ファイルです。ApacheがHTTPリクエストを受信した際に、どのように応答すべきかを定義します。
1ServerName [サーバのドメイン名 or IPアドレス]
2
3WSGIDaemonProcess api_project python-path=/var/www/app python-home=/var/www/app/venv
4WSGIScriptAlias / /var/www/app/app.wsgi
5
6<Directory /var/www/app>
7 WSGIProcessGroup api_project
8 WSGIApplicationGroup %{GLOBAL}
9 Require all granted
10</Directory>
例えば「WSGIScriptAlias」部分は「/」(ルート)にアクセスしてきた際に「var/www/app/app.wsgi」に転送するという設定をしています。
次に「var/www/app/app.wsgi」を以下のように記載して保存します。
1!/var/www/app/venv/bin/python3.10 #Pythonのパスを設定
2import sys
3sys.path.insert(0, "/var/www/app")
4from app import app as application「from app import app as application」の部分はapp.pyからappという箱を作って、それにapplicationという名前をつけたイメージです。「wsgi」モジュールはこの箱を使ってWebサーバとやりとりしてくれるイメージです。
次に開発環境の「src」フォルダ下のファイル一式を「/var/www/app」下へ配置します。
最後にApacheのサービス再起動して完了です。
sudo systemctl restart apache2以上までが「WebサーバへAPI資材をデプロイ」の手順となります。
自分の端末からHTTP通信経由でAPIにアクセスしてみます。
1curl -X POST http:/[自分のサーバホスト名]/chatgpt_prompt \
2-H "Content-Type: application/json" \
3-H "Authorization: Bearer [ChatGPTのAPIキー]" \
4-d '{
5"model": "gpt-3.5-turbo",
6"messages": [{"role": "user", "content": "Can you help me?"}],
7"max_tokens": 1000,
8"temperature": 1.0
9}'回答が返ってきましたね。めでたしめでたし。

本記事は以上となります。



