【Python×Make】天気予報をLINEへ自動配信
SANA Sanao Tech Lab

こんにちは。先日、X自動ポストの仕組みをご紹介しましたが、今回はその進化版として、さらに実用性を高めたシステムをご紹介します。
最初のシステムを構築して半年以上運用してわかったのは、画像を含む投稿がユーザーとのエンゲージメントを劇的に向上させるという点です。また、ポスト内容の管理をデータベース化することで、更新や追加作業が驚くほど効率的になりました。
今回は例としてデータベースの中からランダムで選ばれたオススメの映画を画像付きでポストするシステムを構築します。先に完成図を見せるとこんな感じです。

このシステムは他の用途にも応用可能で、自動化されたX運用によってマーケティング活動や情報発信をさらに強化する強力なツールとなるでしょう。
また、今回も基本的な構築は無料で行うことが可能です。自動化による効率化に真剣に取り組みたい方は、この機会にぜひ進化したBotの作成方法をご覧ください。
かなりのボリュームになっていますが、皆様にとって価値のある記事となっていると信じていますので最後まで読み切っていただけると幸いです。
今回のシステム構築の流れは以下となっています。STEP1〜STEP3は事前準備のため、解説はSTEP4の「システム設計」から始めます。
自動化ツール『Make』のアカウントを取得します。
下記から登録いただくと1ヶ月間Proプランが無料です。
Makeについては以下の記事で使い方の紹介をしています。

下記の記事の「事前準備」の章にてXのAPIキー情報を取得してください。

ポストする画像はGoogle Driveに保存して、APIを通じて読み込む仕組み構築します。下記の記事を参考にGoogle APIを有効にしてください。

今回構築するデータベースや画像取得処理、及びMakeの処理フローを設計をします。
Make上のモジュールを組み合わせてシステムを構築していきます。APIキーの設定方法や、画像を含むポストの具体的な設定方法も説明します。
Make上に構築したモジュールが正常に動作することを確認し、画像を含むポストが正しく行われることをテストします。
スプレッドシートに記載されたデータをデータベースへ自動収録できる機能を実装します。この機能により大量のデータを簡単に登録することができます。
まず最終的にフォーマットでポストしたいかを考えます。
以下が「Make」上のXポスト用のモジュールです。例としてこんなレイアウトでポストできるようにシステムを構築してみましょう。
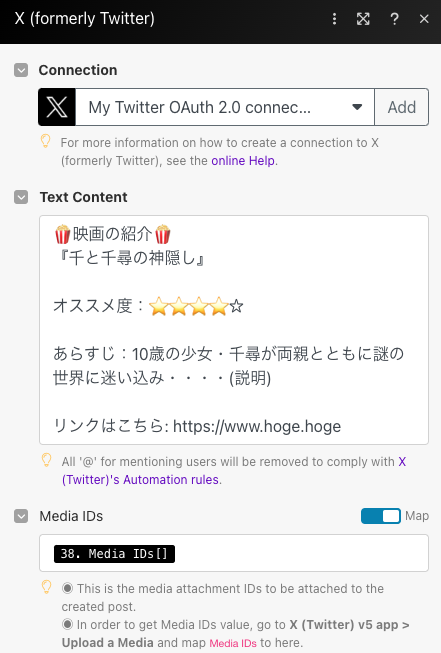
まず、「Text Content」内の「映画タイトル」「オススメ度」「あらすじ」「映画へのリンク」については自由に決められる部分(変数)とします。
つまり、{}を変数とするとレイアウトは以下となります。
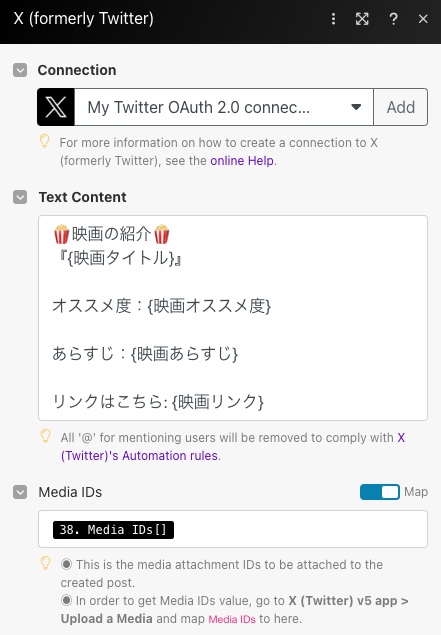
また、「Media IDs」の部分が画像の情報を埋め込む項目となります。この画像については事前にGoogle Driveに保存されているものを呼び出すようにします。映画のタイトルと画像を紐づけていく必要があるのでその辺りは次章で説明します。
今回はMakeにあるData storesの機能を使ってポストする内容を管理します。My SQLやPostgreSQLと違ってインストール等の作業が必要なく、簡単にデータベースを作成することができます。ただし、主キーや外部キーの設定などの機能はないのでご注意ください。
まずはデータベースの設計をします。今回は1テーブルしか作成しないのでシンプルです。
| # | 論理名 | 物理名 | 型 |
|---|---|---|---|
| 1 | 映画ID | MOVIE_ID | NUMBER |
| 2 | 映画タイトル | MOVIE_TITLE | TEXT |
| 3 | 映画あらすじ | MOVIE_SUMMARY | TEXT |
| 4 | 映画オススメ度 | MOVIE_RATING | TEXT |
| 5 | 映画リンク | MOVIE_LINK | TEXT |
#1の「映画ID」は後に大量データを投入する際のスプレッドシート上の管理番号です。#2-#5まではポスト内容に含まれる項目を管理します。
実際にテーブル構築する際には物理名を使用します。
ポストする画像はオススメする映画と対応させる必要があります。そのため、映画IDと画像を紐づけて取得します。今回、以下の命名規則を使用します。
「#{映画ID}_{画像配番}」
具体例として挙げると「#1_3」、「#100_4」などです。画像はXの仕様上、4つまでなのですが、今回は1〜2までとします。
Xの場合、画像付きポストをする場合はAPIを通じて画像をXにアップロードしてMedia IDを取得する必要があります。
以上より画像取得処理をまとめると以下となります。
上記を基にMakeの処理を以下にまとめます。
以上で設計が完了しました。それでは実装を進めていきましょう。
前章の設計を基に実装を進めていきます。
まずはデータベースの実装から始めます。
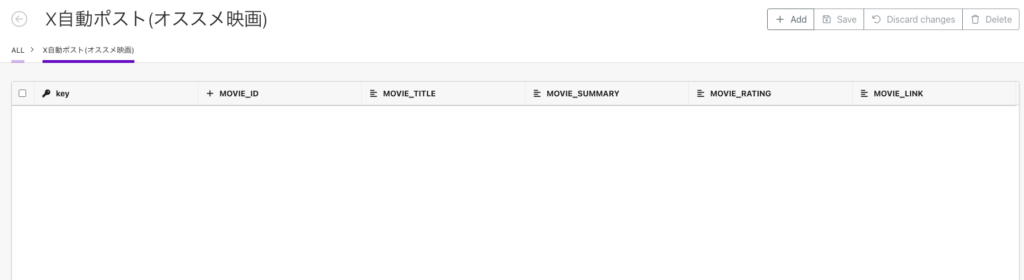
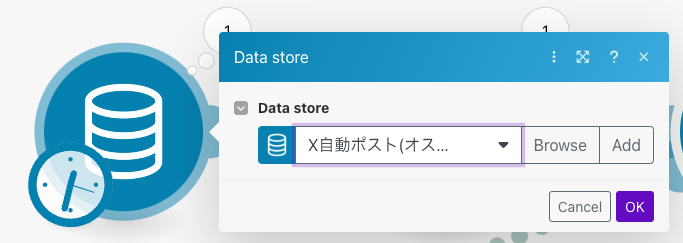
Make画面の左にある「Data stores」をクリックして「Add data stores」にてデータベースを追加します。各カラムについては前章で設計した設定してください。
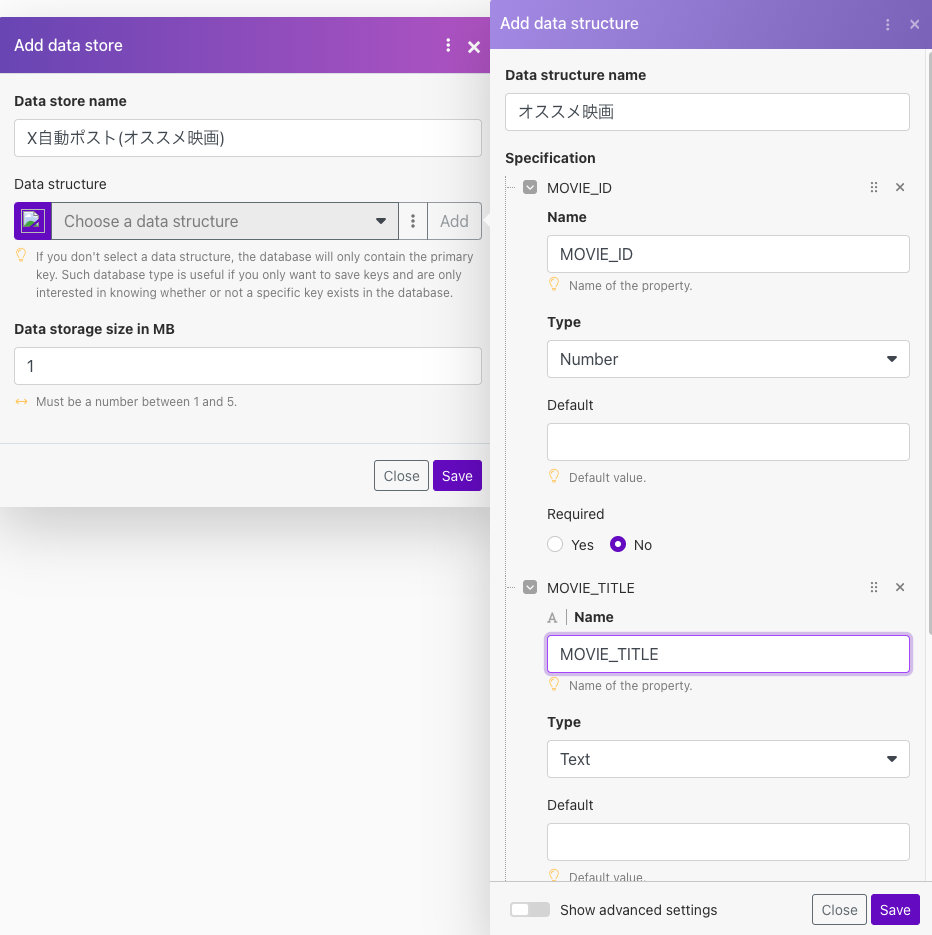
設定したらデータベースを開いてみましょう。こんな感じで表示されればOKです。
ここからはMakeの実装を進めていきます。モジュールの使い方については以下の記事で詳しく解説しています。一読してから進めるのがオススメです。
さて、今回の完成図について先に紹介します。こちらの図を使って詳しい設定値の確認をしていきます。
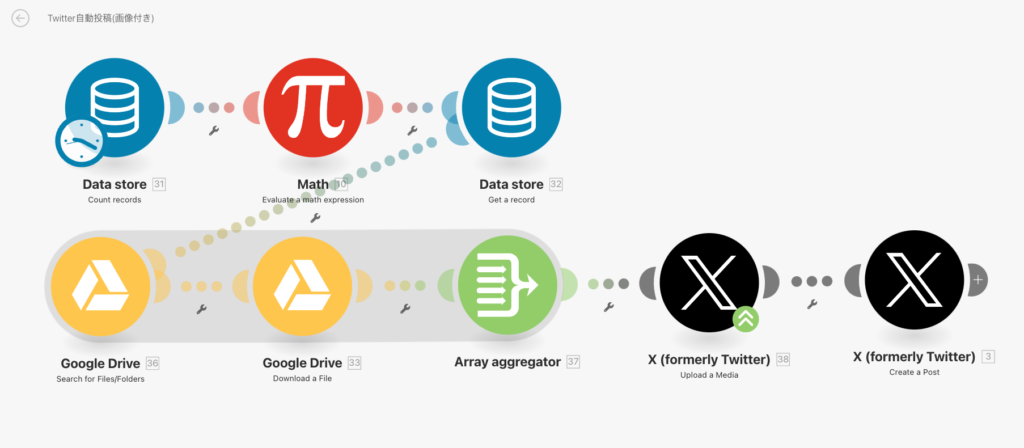
まずはData store(Count records)モジュールを確認しましょう。このモジュールはデータベースに収録されてるレコード総数をカウントします。
次にMathモジュールを確認します。こちらは先ほど取得レコード総数を最大値として1〜レコード数(=映画IDの最大値)から任意の1つの数をランダムで取得します。
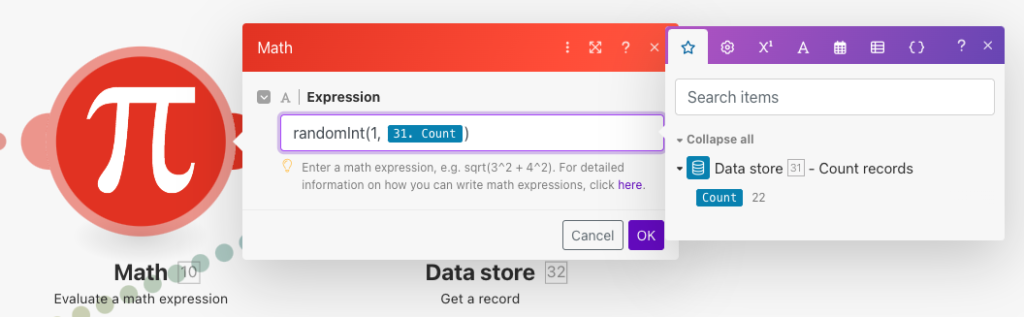
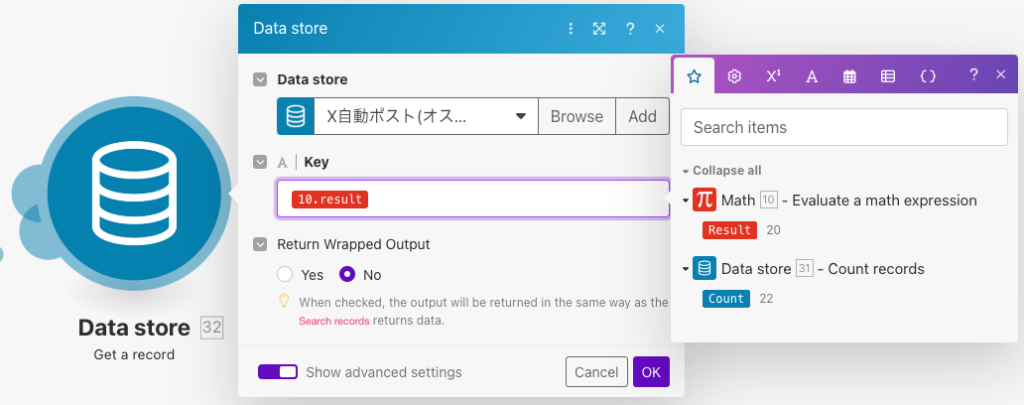
次にData store(Count records)モジュールを確認します。先ほどのMathモジュールで取得したランダムの1つの数をキーとしてデータベースから1レコードを取得します。
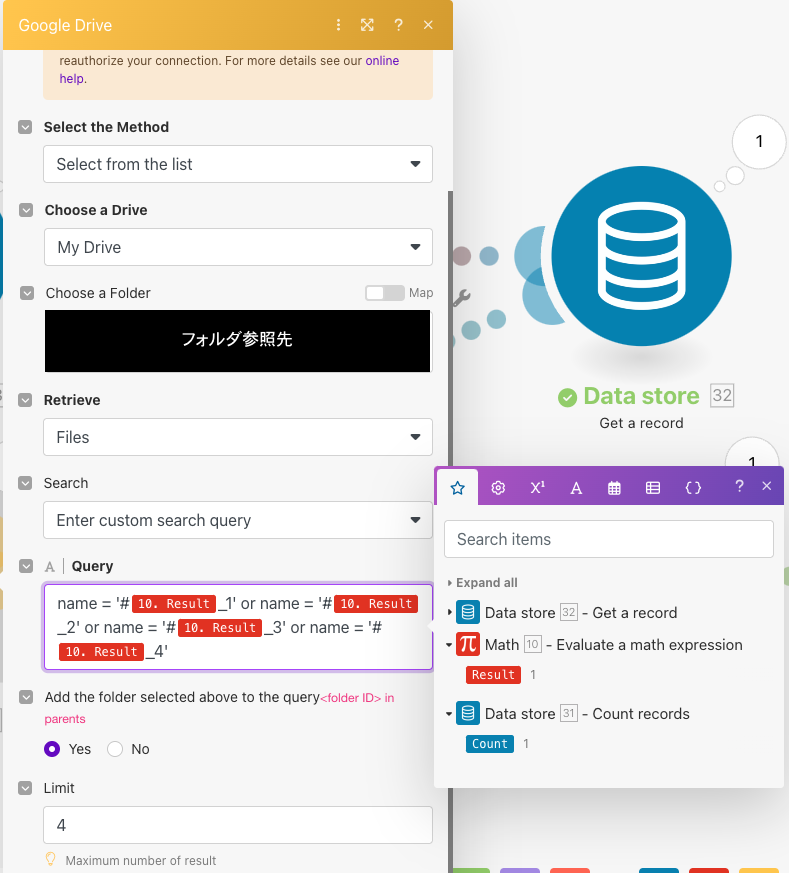
次にGoogle Drive(Search for Files/Folders)モジュールの設定をします。以下に設定値をまとめました。
| 項目 | 設定値 | 説明 |
|---|---|---|
| Retrieve | Files | ファイルを取得します。 |
| Search | Enter custom search query | 条件は手動で入れます。 |
| Query | name = ‘#{Mathモジュールの値}_{画像配番}’ | 変数を含む条件をセットします。 |
| Limit | 4 | 最大4の検索結果を返却します。 |
次にGoogle Drive(Download a File)モジュールの設定をします。前のモジュールで取得したFile IDを基に画像のダウンロードをします。

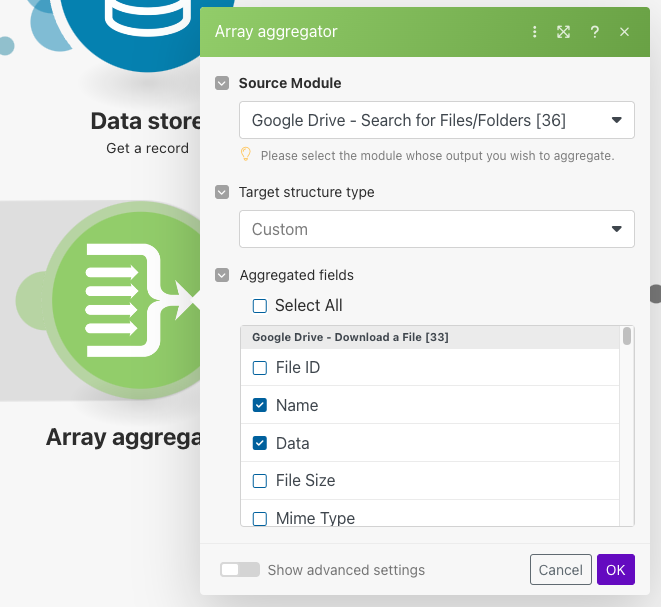
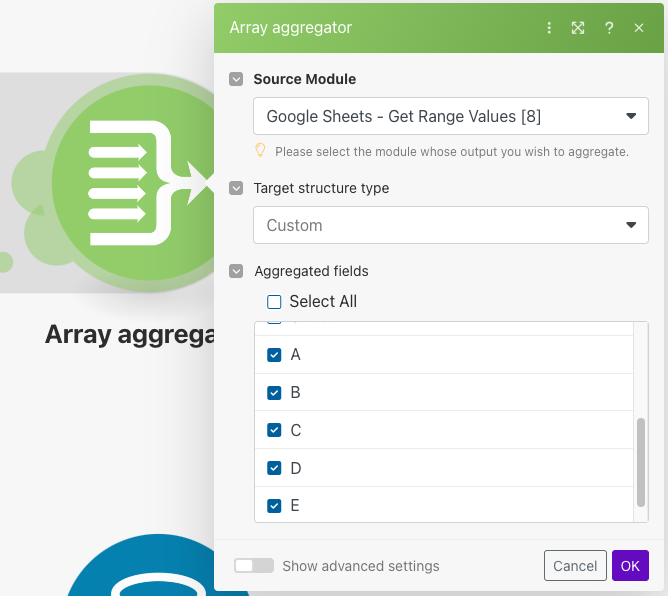
次にArray aggregatorモジュールを使用することでダウンロードしたファイルをリストで保持します。後続で使用するのが「Name」と「Data」なので、そちらの情報のみ取得するよう設定をします。
次にX(Upload a Media)モジュールを使って画像データをXにアップロードしてMedia IDを取得します。
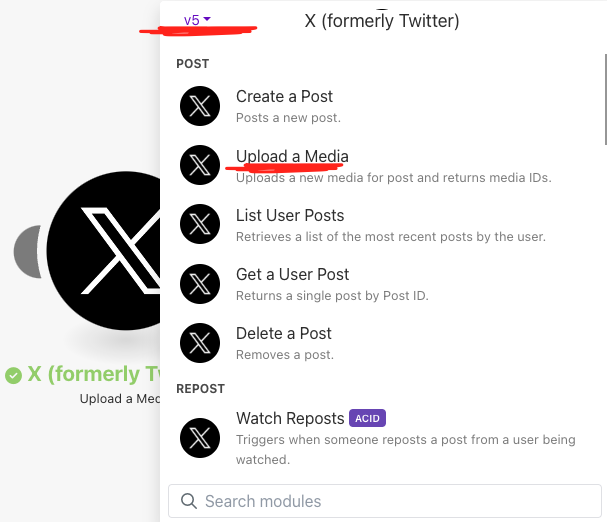
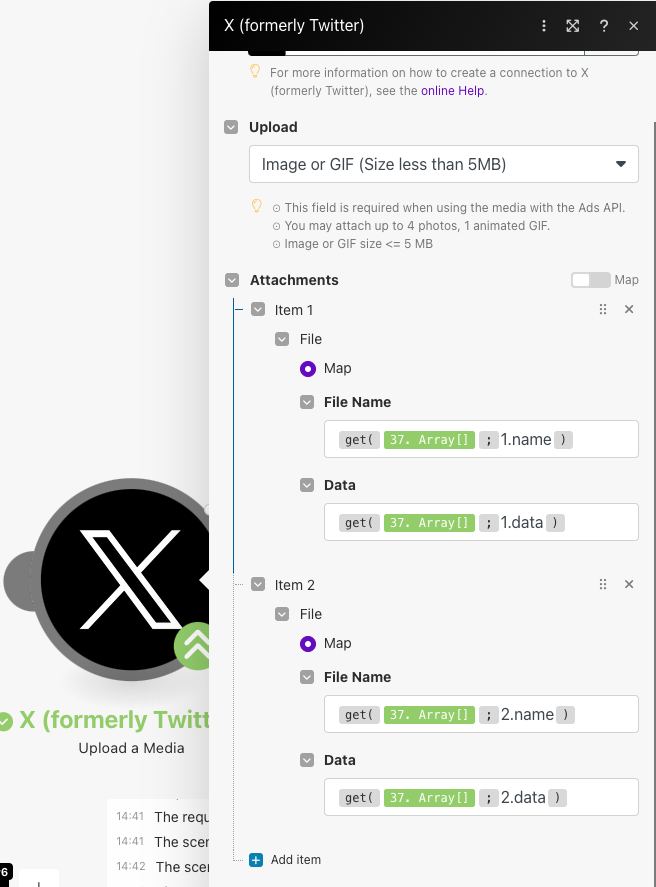
File Name、Dataの各項目にはリスト(Array)から取得した「name」「data」をセットします。
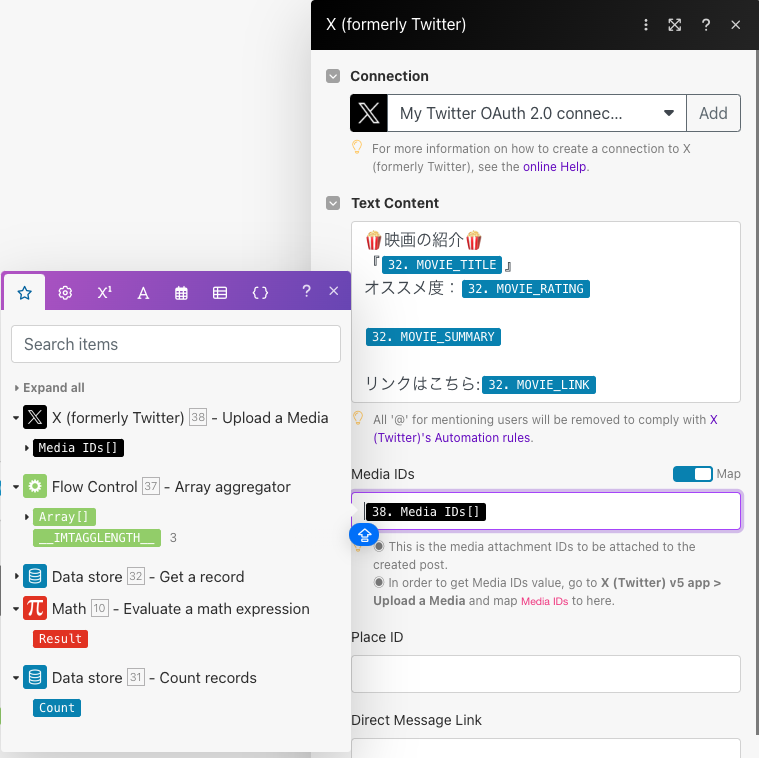
最後にX(Create a Post)モジュールに各値をセットします。冒頭の方で見せた通り、以下のようのようなレイアウトにしました。
これでMakeの実装は完了です。
まずはデータベースに値を入れてみましょう。

Keyが#1なので、GoogleDrive上に#1_1と#1_2のファイル名で画像を保存しておきます。
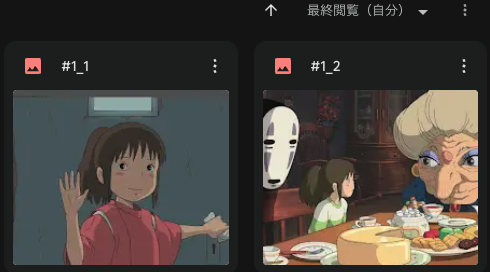
シナリオの左下にある「Run Once」ボタンを教えてみましょう。こんな感じでポストされてると思います。
これで疎通確認は終了です。
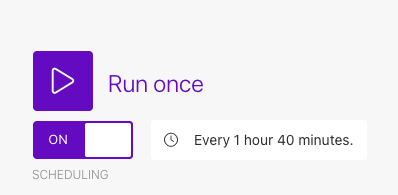
シナリオを定期的に実行する必要があるので、自動投稿の設定をします。
シナリオの左下の方にあるSHEDULINGをONにして時間を設定しておきます。今の設定だと1時間40分ごとにシナリオが稼働し、自動ポストが実行されます。
こちらは自動ポスト機能と別のものとなります。そこまで難しいロジックなどもないので、簡単に説明してしまおうと思います。
構築するシステムはGoogle Spreadシートに記載されたポスト内容をデータベースに登録するシステムを構築します。これにより大量のデータをデータベースへ登録することが可能となります。
処理フローは以下のようにします。
ファイルレイアウトはデータベースのレイアウトに合わせます。
| # | 論理名 | 物理名 | 型 |
|---|---|---|---|
| 1 | 映画ID | MOVIE_ID | NUMBER |
| 2 | 映画タイトル | MOVIE_TITLE | TEXT |
| 3 | 映画あらすじ | MOVIE_SUMMARY | TEXT |
| 4 | 映画オススメ度 | MOVIE_RATING | TEXT |
| 5 | 映画リンク | MOVIE_LINK | TEXT |
実際のスプレッドシートは以下のようになっています。こちらインプットのファイルとして

まずはMakeの全体図をお見せします。各自モジュールの設定値について説明をしていきます。
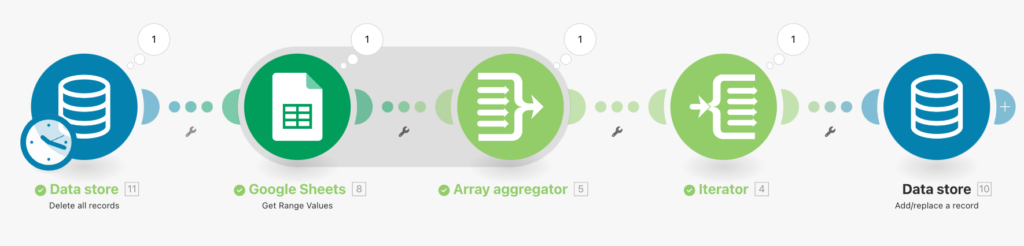
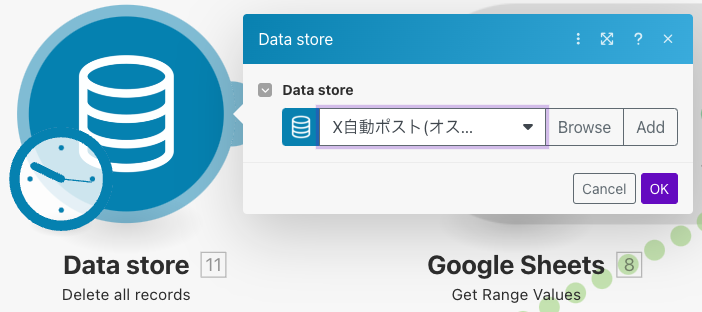
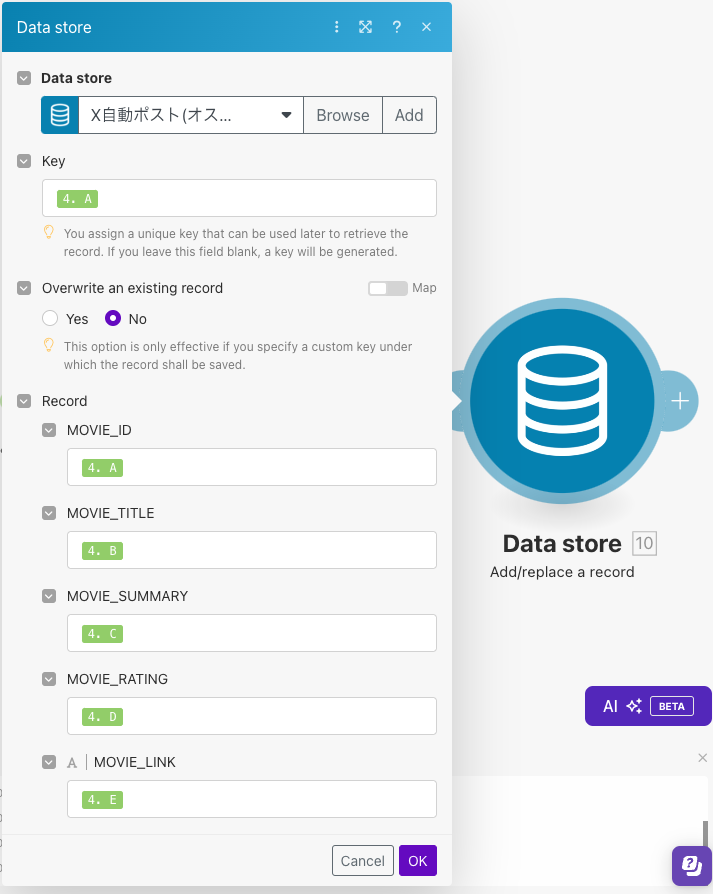
まずはData store(Delete all records)モジュールにデータベースを登録します。このモジュールによってレコードを全削除します。
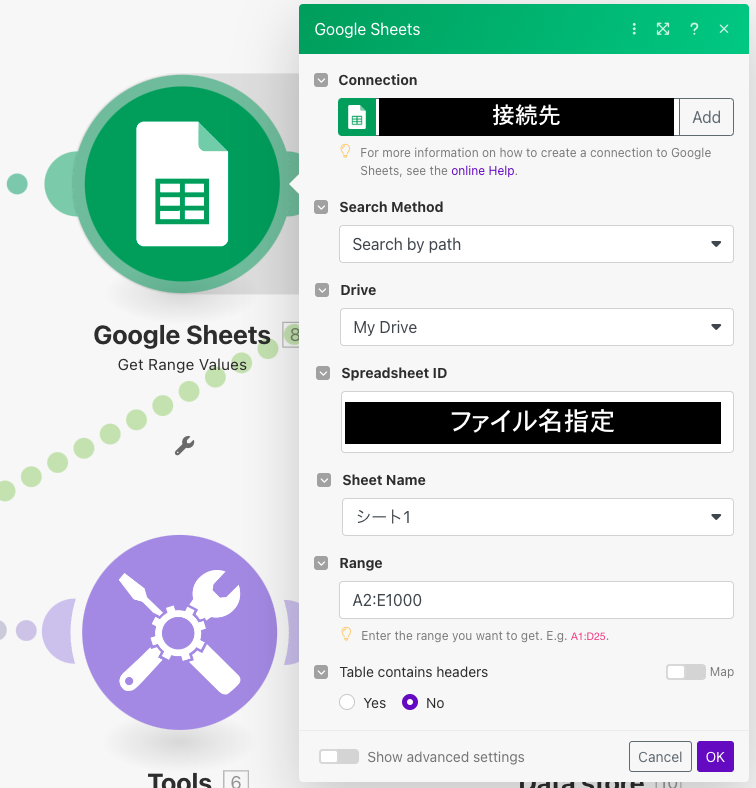
次にGoogle Sheetsのモジュールを使用して、表内の値を取得します。RangeはA2:E1000としていますが、データ量に応じて調整してください。
次にArray aggregatorモジュールを使ってA〜E列の値をリスト化します。
最後にData store(Add/replace a record)モジュールを使ってリスト化されたデータをデータベースに収録します。
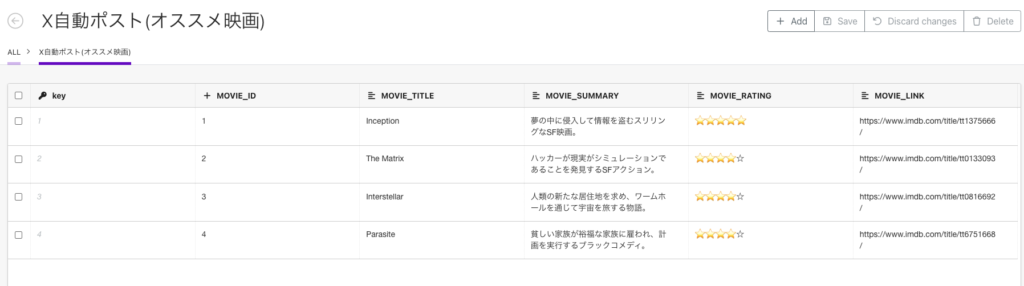
シナリオの左下にある「Run Once」ボタンを押してみましょう。シナリオが正常狩猟した後にデータベースを見て以下のようになっていれば成功です。
ここまで読んでいただきありがとうございます。かなり長い解説記事となってしまいましたが、なるべく丁寧に書いたつもりです。冒頭にも申し上げた通り、今回のシステムは様々な用途に応用できると思いますのでぜひ有効活用していただけると幸いです。